7 minutes
Do you really know Git?
Git. Everyone knows it. Everyone uses it. Maybe you love it, maybe you don’t. Either way, do you really know it?
Personally, I like to have a deep understanding of how something works or how it is made. This is cool for stuff like wine and cooking. However, when it comes to work related topics, it can be a bit of a hindrance because my head simply refuses to accept things as they are before knowing MOAR.

This was the case with Git. In the beggining I ran into a bunch of problems and unknown territories, such as branching and merge conflicts. The kind of problems that twist your head so much that you just copy your code into a new repository. Since then I’ve been learning a lot both on the job and by studying in depth topics.
Enought chit chat. Let’s get into Git.
Into Git
Now, anyway who has worked with this tool knows at least the basics of Git’s interface: init, status, push, pull, commit, merge and so on.
This is fine for many cases but every now and then we’re inevitably faced with some situation that is slightly more complex. This is when we go online, search on Google, and land on a few StackOverflow posts where people suggest a myriad of Git commands full of options and flags that you don’t recognize. You copy, you paste. Pray. Enter. Solved! Great… But you have no idea what you just did (which could be harmful) and you’ll have to waste time again when encontering a similar problem.
The first step in the direction of illumination is understanding Git’s data model.
Data Model
So, what does Git do for us? It keeps the version history of directories and files (that live under a root directory).
In Gitspeak, directories and files are trees and blobs. Trees are a recursive data structure, containing trees and/or blobs.
# This example has 2 trees (., content); 2 blobs (Makefile, about.md)
# . is the root directory: everything inside can be tracked by git
.
├── Makefile
└── content
└── about.md
What about history? If you’re familiar with Git, you are well aware of commits. Commits are essentially snapshots of the repository content state, bundled together with some metadata (author, message, timestamp…) and references to its parents.
These are the building blocks of Git. To help visualize them, let’s see how we could define these constructions in a Golang-ish pseudo code.
// a blob/file is simply an array of bytes
type Blob []byte
// a tree maps a file/directory name into a blob or a tree, respectively
type Tree map[string]<Tree | Blob>
// a commit holds some metadata, an array of parents
// and a snapshot of the repository tree at the time of the commit
// note: *Commit/*Tree represent pointers but these could be strings because what Git stores is the object hash (explained ahead)
type Commit struct {
author string
message string
timestamp Time
parents []*Commit
snapshot *Tree
}
Quite straightforward. The most interesting part being the parents of a commit. A commit can have 0 parents (an initial commit), 1 parent or 2 parents (a merge commit).
In conclusion, Git’s version history is a directed acyclic graph.
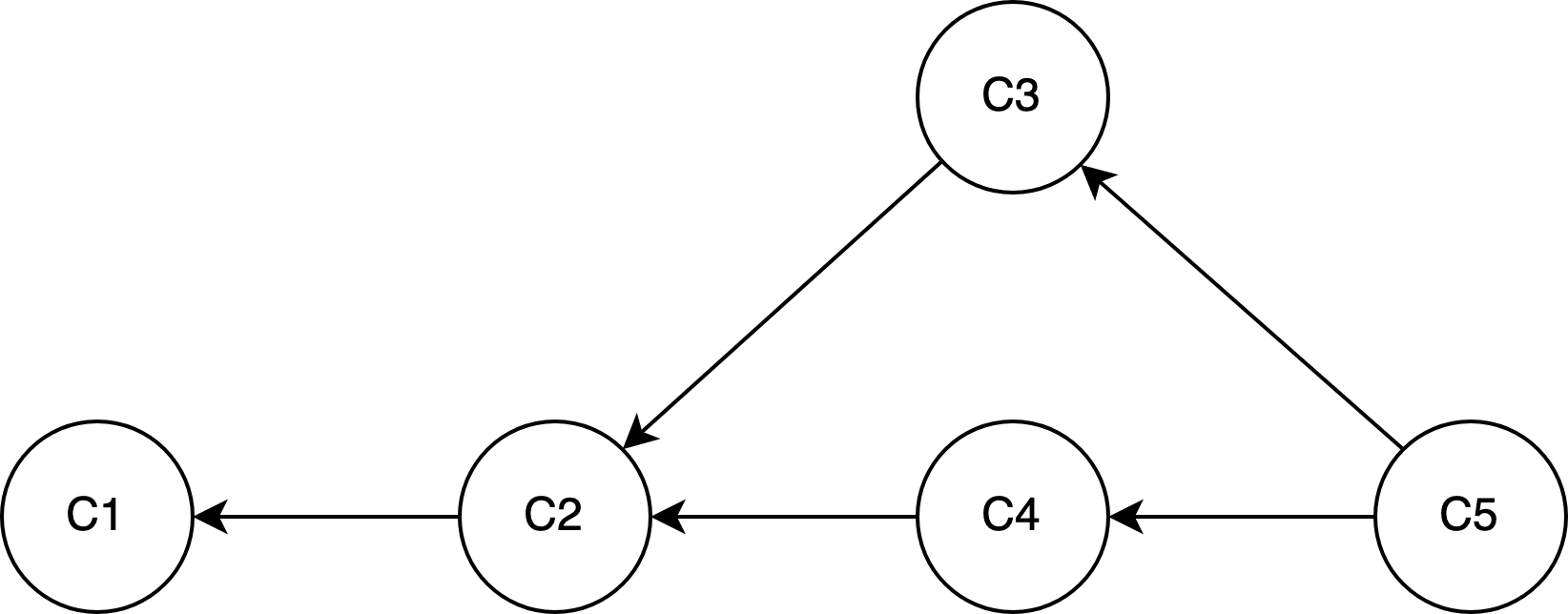
It’s common to think about version history as a tree. However, in a tree, a node can only have 1 parent and there can only be 1 tree root.
In a directed acyclic graph, a node can have any number of nodes pointing to it.
Also, it’s possible to have orphan and disconnected nodes. See the docs for
git checkout --orphan <new_branch>:(…) The first commit made on this new branch will have no parents and it will be the root of a new history totally disconnected from all the other branches and commits. (…) This can be useful when you want to publish the tree from a commit without exposing its full history. You might want to do this to publish an open source branch of a project whose current tree is “clean”, but whose full history contains proprietary or otherwise encumbered bits of code.
Objects
To Git, blob, tree and commit are all objects. Objects are the basic storage unit of Git, meaning that all data is stored as an object in content addressalble storage.
In simpler terms, Git keeps all objects in a key-value data store.
The value, as we’ve seen, is either a blob, a tree or a commit. The key, is a SHA-1 hash of the object content being stored (plus a header).
When created in the Git database, the object files are accessible in .git/objects. In here, Git organizes the objects by creating subdirectories named with the first 2 characters of the SHA-1 hash, the filename being the remaining 38 characters.
In Action
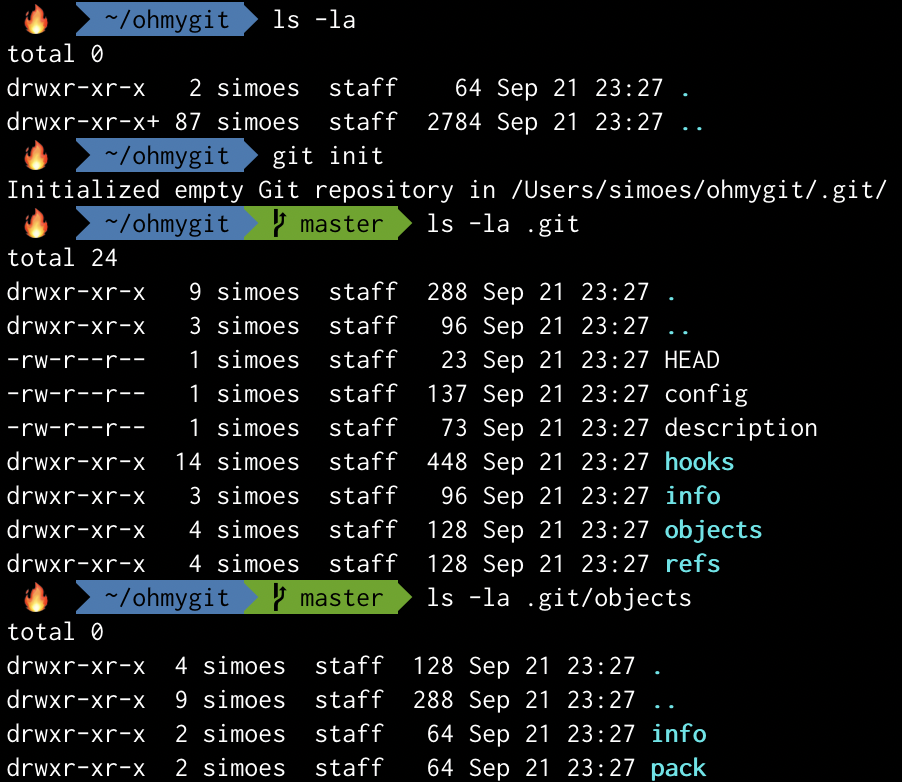
Let’s start by creating an empty directory and then initializing a repository there. Notice the objects directory.
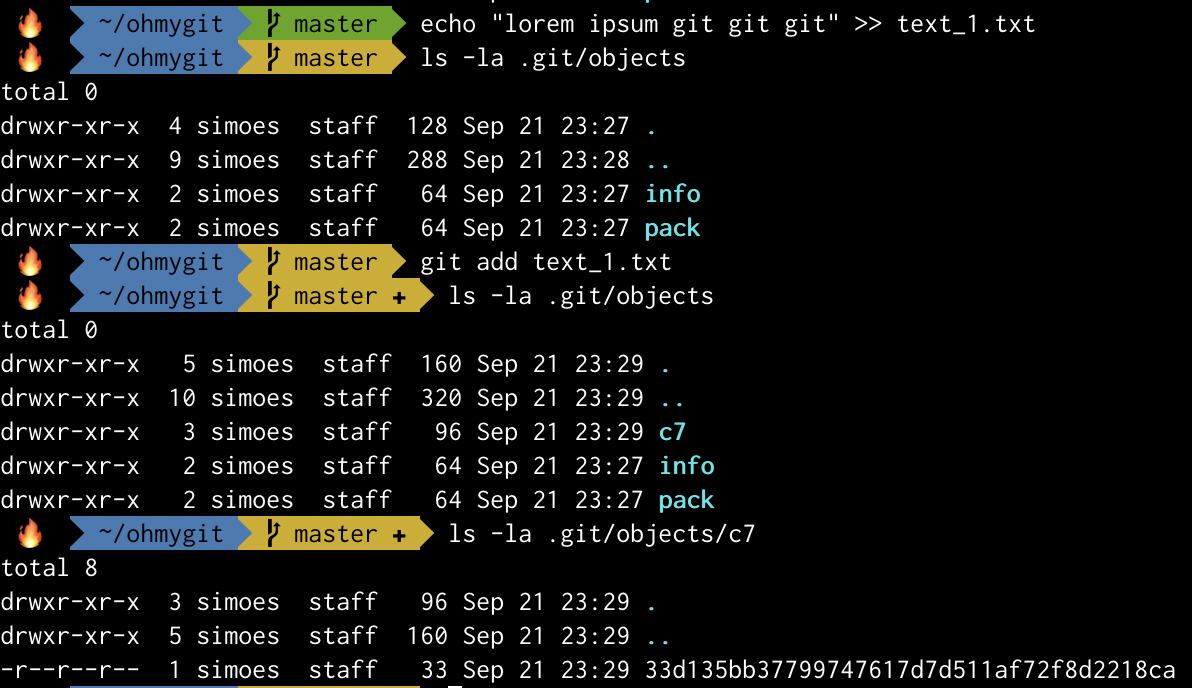
Next, I created a simple text file and listed the contents of objects. Nothing changed because the file is still not part of Git’s staging area (or index). After adding it, it is now visible as .git/objects/c7/33d135bb37799747617d7d511af72f8d2218ca (the object hash is c733d135bb37799747617d7d511af72f8d2218ca).
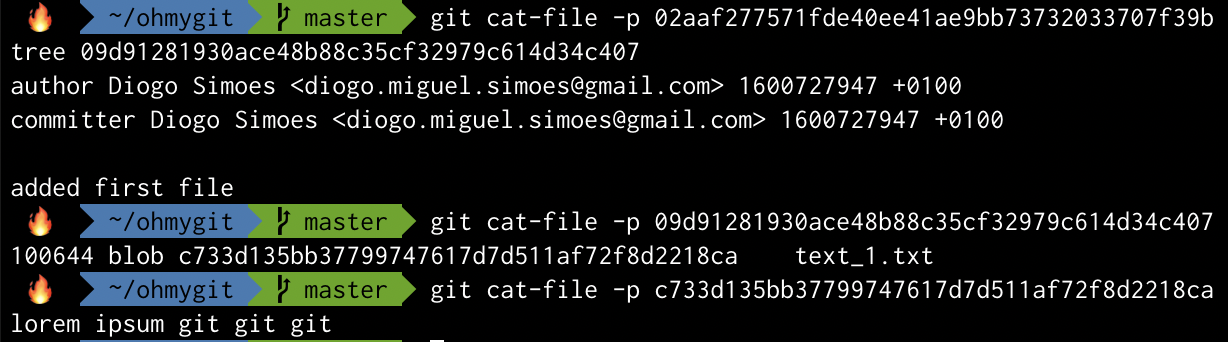
The content of an object can be see with git cat-file:

Now, let’s make a commit and see if a new object is created.
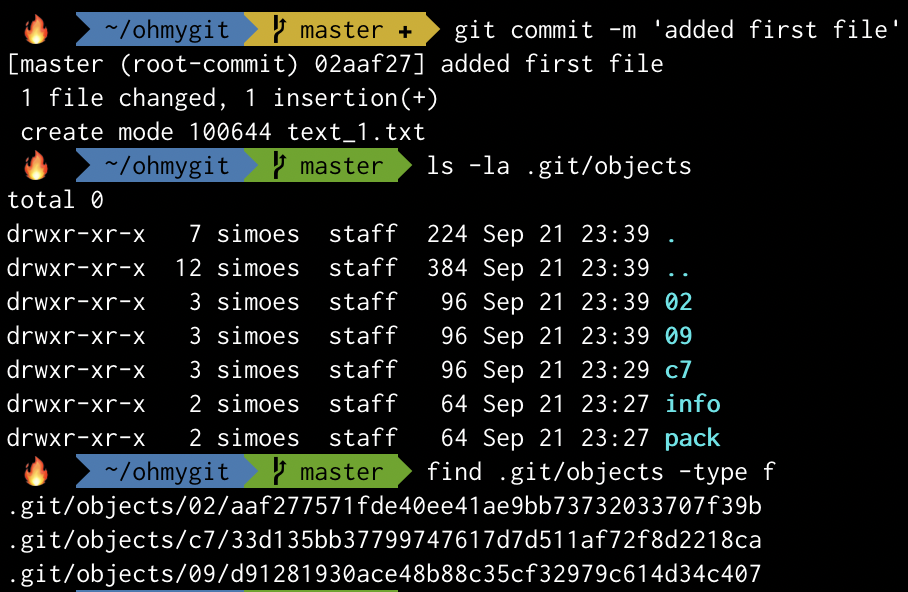
Heh! Two more file. Remember: a commit contains a snapshot of the repository, which is a tree object. So now we must have 1 commit, 1 tree and 1 blob.
Let’s print them all to verify this.
We shall see what happens when I add a new file a new commit:
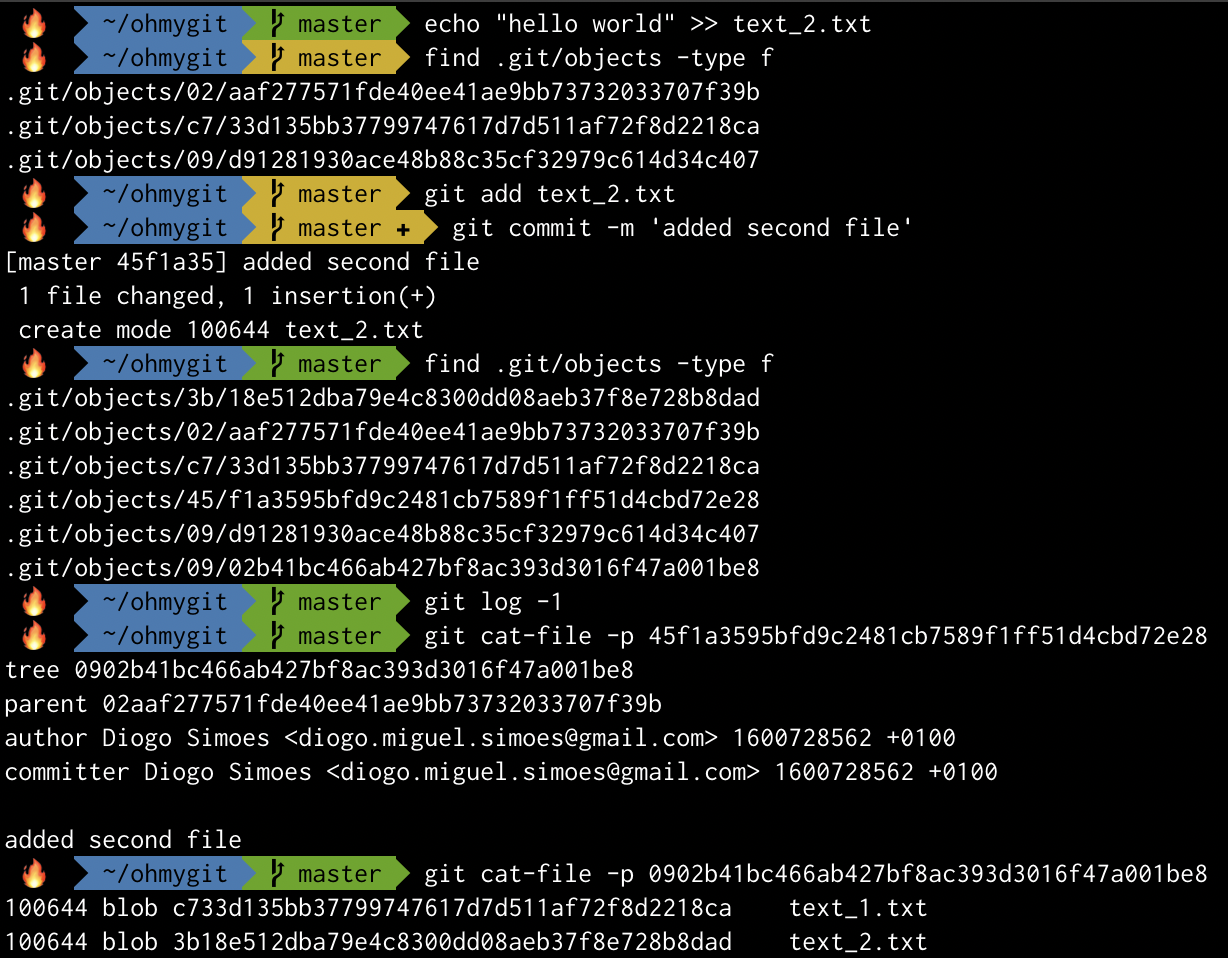
We have a few more objects (2 per type). Also, the new commit now shows a reference to its parent.
Notice the tree still refers to text_1.txt by the original hash c733d135bb37799747617d7d511af72f8d2218ca because the file content did not change.
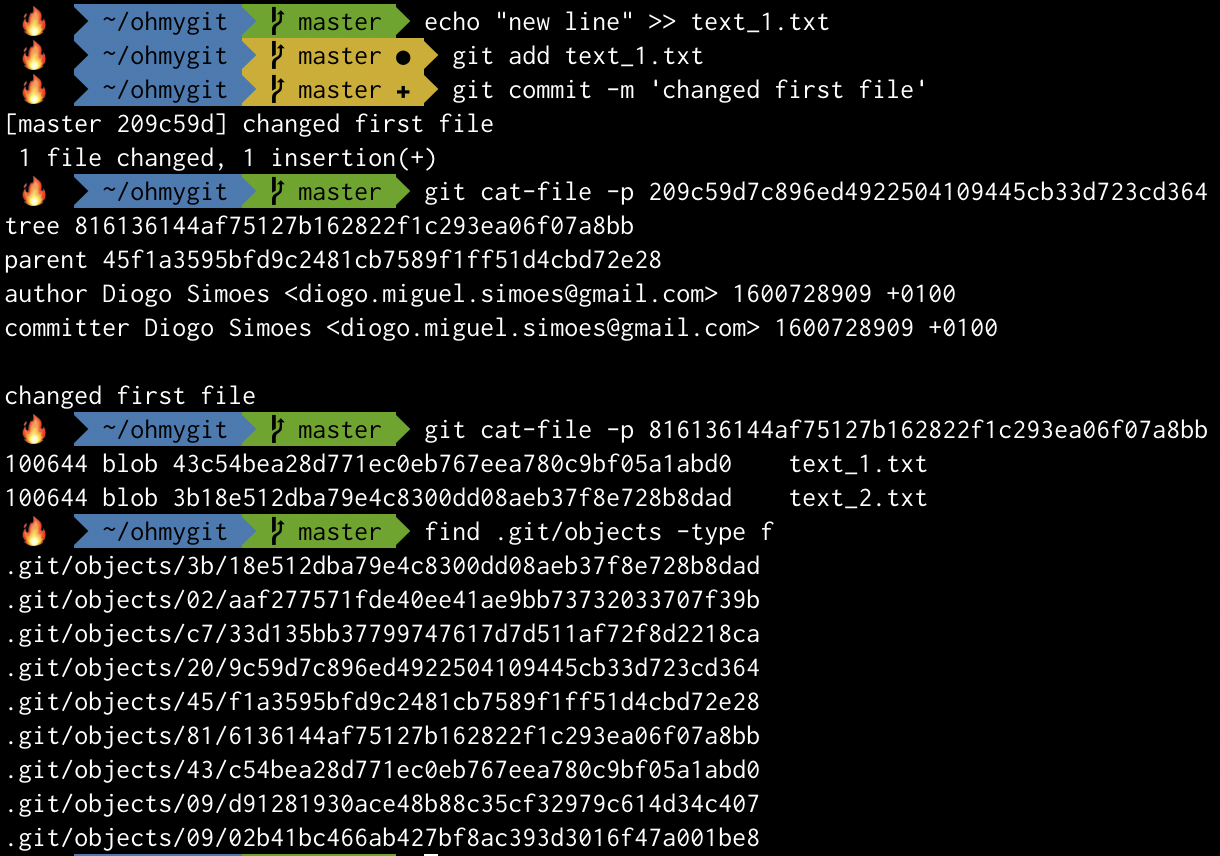
The tree of the third commit now shows a different hash for text_1.txt. This is the file’s new version. The previous one is still there, of course, since it’s still part of the database and the repository history (still referenced by other trees).
I’m Not a Robot
Even if you have not used Git extensively, I’m sure you know people don’t go around handling SHA-1 hashes all the time.
Git makes our (human) lives easier with references.
References are simply human readable pointers to object hashes.
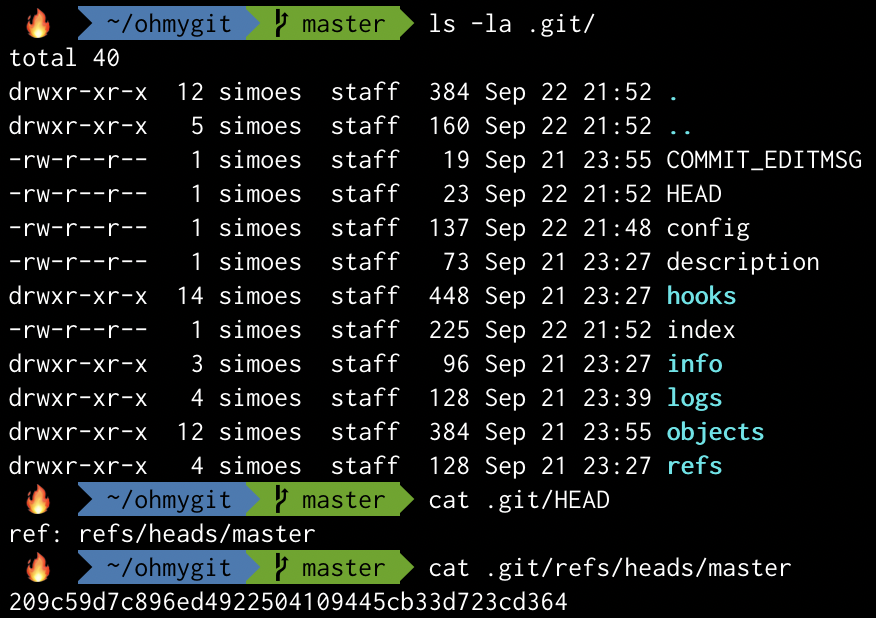
Above we saw that:
- similarly to objects, there is a
refsdirectory where references are kept - there is a special ref called
HEADthat is a symbolic reference to the branch we’re currently on (a ref that points to another ref) .git/refs/heads/masterpoints to our most recent commit- the previous item exposes that branches are simply references
Let’s look again at git log to revisit the representation of HEAD and master.

HEAD points to master, which points to the most recent commit 209c59d.
The HEAD reference is special and, despite most of the times pointing to our current branch, it can also point to another Git object, for example, when we checkout a specific commit.
In the image below I’m checking out the second commit (reverting my repository state to that snapshot).
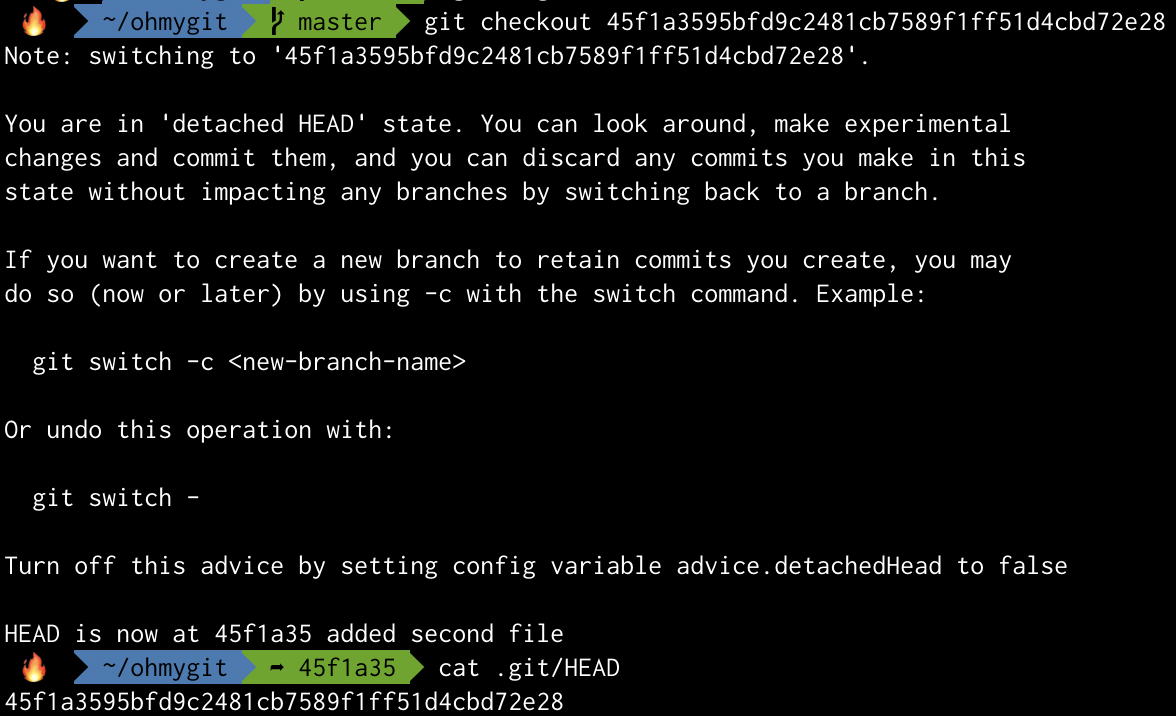
See the difference in .git/HEAD’s content. It now contains the hash of the commit I checked out.
Git also presented me with the scary “detached HEAD” warning. Do not worry. It simply means HEAD is detached from another reference and is instead pointing directly to an object.
Yes, I said scary. When I saw this in my early Git days and had no idea of what it meant, it always gave a sense of “I’m gonna break something”.
That’s exactly the point of this post. Getting confortable with Git by getting to know its internals. Try reflecting about what a merge or a rebase do, for example. Look online for explanations and tutorials on those topics and you’ll see that knowing Git’s inner workings will help you understand them quickly and better.
1320 Words
2020-09-22